Our contribution:
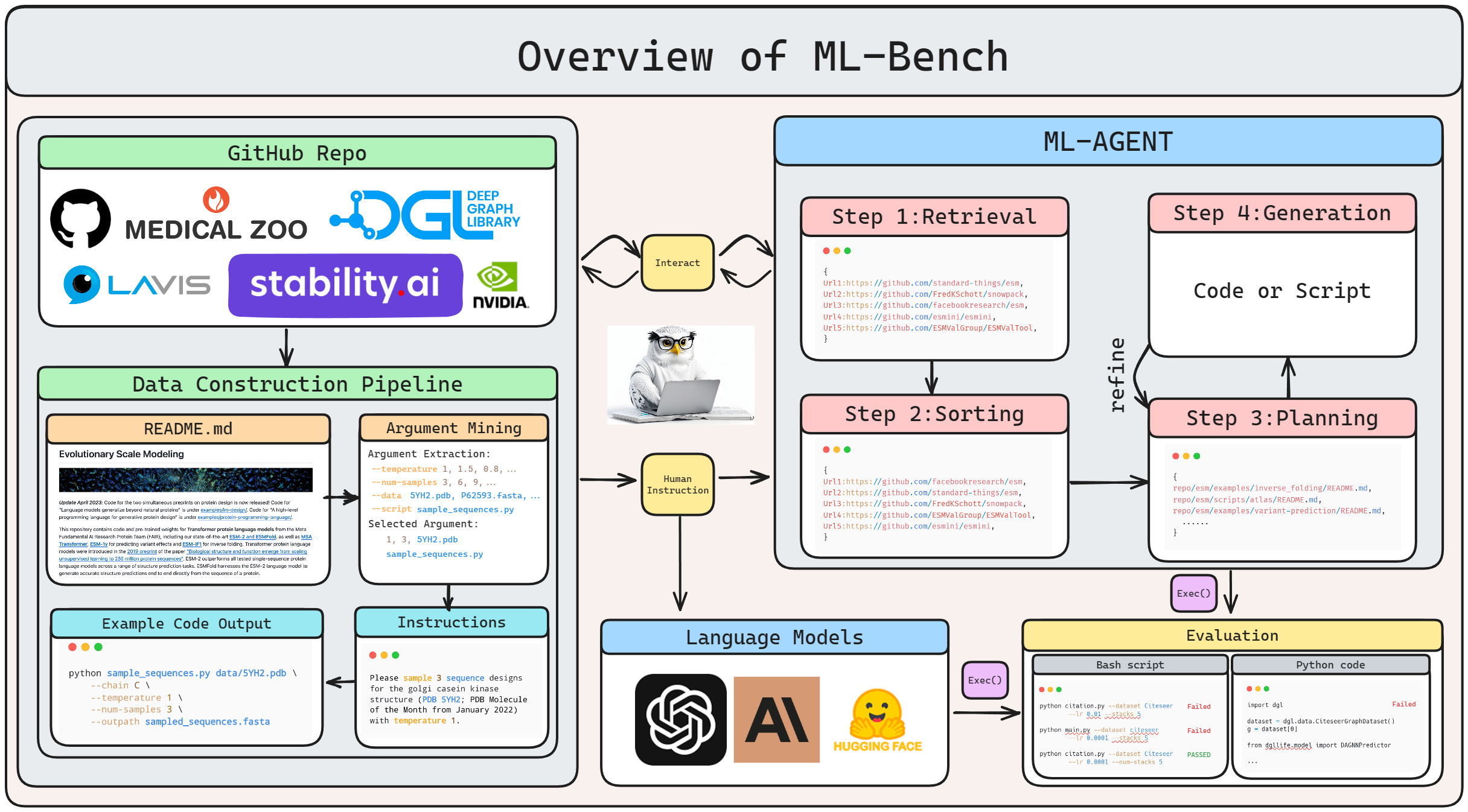
1. ML-Bench provides a comprehensive benchmark for LLMs, focusing on repository-scale code interpretation and end-to-end execution. It addresses gaps in current benchmarking and challenges models with real-world programming tasks.
2. By featuring 9,641 examples across 18 GitHub repositories and employing two distinct setups, ML-LLM-Bench and ML-AGENT-Bench, ML-Bench assesses the capability of LLMs to generate executable scripts and autonomous agents to perform complex coding tasks in a Linux sandbox environment.
3. The benchmark reveals significant room for improvement in current LLMs, as demonstrated by issues with hallucinated outputs and bash script generation challenges, while also confirming the potential for iterative action and feedback to enhance performance in complex task resolution.
1. ML-Bench provides a comprehensive benchmark for LLMs, focusing on repository-scale code interpretation and end-to-end execution. It addresses gaps in current benchmarking and challenges models with real-world programming tasks.
2. By featuring 9,641 examples across 18 GitHub repositories and employing two distinct setups, ML-LLM-Bench and ML-AGENT-Bench, ML-Bench assesses the capability of LLMs to generate executable scripts and autonomous agents to perform complex coding tasks in a Linux sandbox environment.
3. The benchmark reveals significant room for improvement in current LLMs, as demonstrated by issues with hallucinated outputs and bash script generation challenges, while also confirming the potential for iterative action and feedback to enhance performance in complex task resolution.